Fundamental Design Issues of Gradle Build System

As an infrastructure engineer, I spend a lot of time supporting development environments. My work includes build support (mostly JVM/Android as target platforms), as well as writing CLI tools, supporting CI, writing infrastructure backend services, Kubernetes, etc.
Today I'm going to focus on builds, particularly on Gradle and discuss several major issues in its design and suggest potential backwards compatible solutions.
Table of contents
Notes:
"Module"in the article means"Project"in terminology of Gradle API"Project"in the article means entire Project including all of its Modules- Article covers Gradle as of 5.0
- If you find a mistake, inaccuracy or straight blatant lie — reach out, all edits will be credited to their authors, or you can just destroy me in comments, that's fine too
- Article is an opinion of Artem Zinnatullin who is not part of Gradle team nor does it reflect opinions of Artem's employer
Here is a photo of my dear friend — Vladimir Tagakov, a software architect, who is wise, pragmatic and successful because he's wearing Gradle T-shirt in mountains of Montana state.

Design Issues and Solutions
Unlike Bazel and Buck, Gradle, unfortunately, doesn't scale well for multi-module projects. Roughly speaking, at around ~500 modules Gradle overhead is impossible to ignore and it gets worse the more modules you add.
Design Issues: Configuration Phase
- Initialization
- Configuration
- Execution
As any other build system, Gradle needs to know what is it that it needs to build: modules and tasks in modules. To figure it out Gradle needs to evaluate configuration files (either Groovy-based build.gradle, or Kotlin-based build.gradle.kts).
During Configuration Phase modules can apply plugins, register tasks, do computations, perform side-effects like file or network I/O and read/modify configuration of other modules.
Design Issue: Configuration is not Cached
Gradle runs the configuration phase every time you build.
I could run gradle assemble and then run it again and again, and each time I will have to wait for Gradle to configure the project even though I haven't changed anything.
This is an unfortunate promise of Gradle API. Plugins and/or user configuration code can and sometimes do rely on the fact that configuration phase runs every time to perform side-effects like setting module version depending on current unix time.
However, if none of your modules perform side-effects, Gradle still evaluates configuration for them for every build.
Following graph is an illustration, it roughly represents the situation in our project with ~830 modules. Hardware: MacBook Pro 2018, Intel Core i9, 32GB of memory, all unnecessary Gradle plugins disabled, Gradle 5.0 and AGP 3.4.0-alpha07.
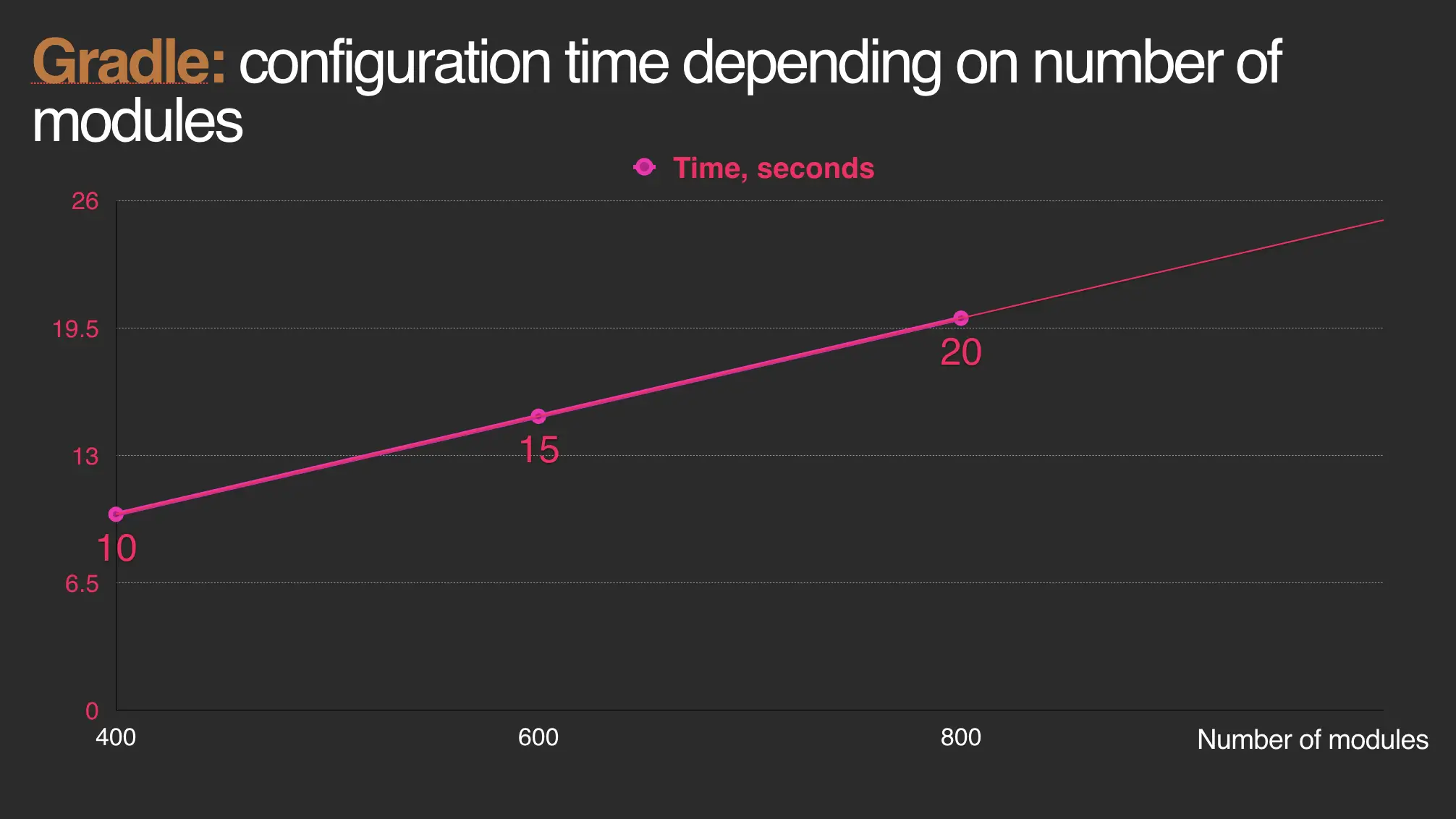
Gradle should cache and avoid configuration of modules.
Proposed Solution: Strict Configuration Mode: Purity
To allow Gradle to cache configuration of a given module, we need to add an opt-in API that would let a module to declare that its configuration is 100% reproducible (meaning that configuration code/plugins don't rely on inputs that change without Gradle's notice).
Luckily, often times configuration is already pure! A module typically applies one or more plugins to support particular programming language like Java or Kotlin and then defines some dependencies. Side-effects should be declared as Tasks and Gradle knows how to handle them efficiently.
For example, configuration of the following module should be cacheable as is, there is nothing impure about it*:
apply plugin: 'java-library'
dependencies {
api 'io.reactivex.rxjava2:rxjava:2.2.1'
}
dependencies {
implementation 'com.google.protobuf:protobuf-lite:3.0.1'
implementation project(':internal-lib')
}
dependencies {
testImplementation 'org.junit:junit:5.1.0'
}
*Of course, one needs to know if a given plugin does side-effects under the hood, but most of the plugins should not do this by design. Gradle has tasks that are meant to represent side-effects (and tasks can be incremental and build-cacheable!).
Configuration however still should be invalidated if:
build.gradleof the module has changed (ideally, only if actual code has changed)- Configuration of a dependent module has changed as it may bring/remove transitive dependencies (ideally, only if there is an actual meaningful change)
Proposed API seem to have to be part of initialization phase (settings.gradle) rather than configuration phase (build.gradle) so that Gradle would know if configuration is cacheable upfront before the actual configuration phase.
Proposed API:
settings.gradle
include ':module-a'
project(':module-a').pure = true
Result:
Such a change will allow Gradle to know configuration of which modules it should cache (in memory/disk/buildcache) and skip it for subsequent builds thus significantly reducing the penalty of the configuration phase for every build after first one.
Design Issue: Configuration is Serial
Gradle configures modules one by one, linearly increasing configuration time with the amount of modules in the project.
This is an unfortunate side-effect of the Gradle API design.
Gradle API allows plugins and/or user code to read/modify configuration of other modules or other global state. Thus there is no easy way for Gradle to configure modules in parallel.
This problem combined with "Design Issue: Configuration is not Cached" results in ~20 seconds configuration time penalty for each Gradle build in the project I work on (~830 modules).
Gradle should configure modules in parallel.
Proposed Solution: Strict Configuration Mode: Isolation
To allow Gradle configuring modules in parallel, we need to add an opt-in API that would let a module to declare that its configuration is isolated from configuration of other modules, meaning that module doesn't modify global state or state of other modules and doesn't rely on initialization order (reading immutable global state that has already been initialized is fine).
For context, Buck is able to configure our project in 2 seconds (without caching) which includes parsing and processing of build files defined in Python/Skylark/Starlark, Gradle needs ~20 seconds for that.
Proposed API:
settings.gradle
include ':module-a'
project(':module-a').isolated = true
Proposed API seem to have to be part of the Initialization Phase (settings.gradle) so Gradle knows this upfront, before the configuration phase.
Result:
Such a change will allow Gradle to know which modules can be configured in parallel, thus making configuration phase significantly faster.
Combined, "Purity" and "Isolation" of the Configuration will allow Gradle to maximize efficiency of the Configuration Phase by caching/avoiding it as well as doing it in parallel if configuration can not be avoided.
Design Issues: Execution Phase
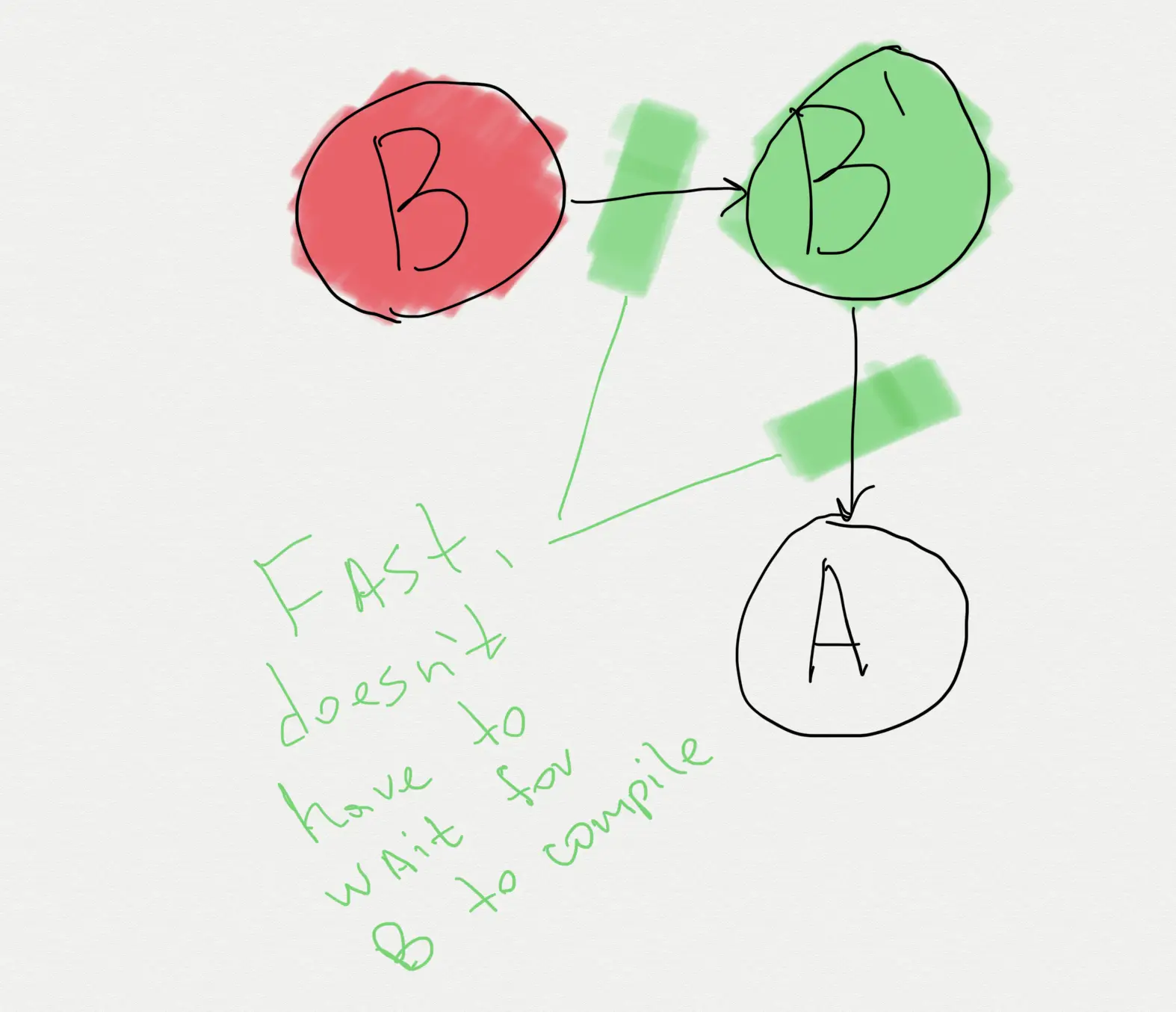
Design Issue: Modules are not Built Against ABI
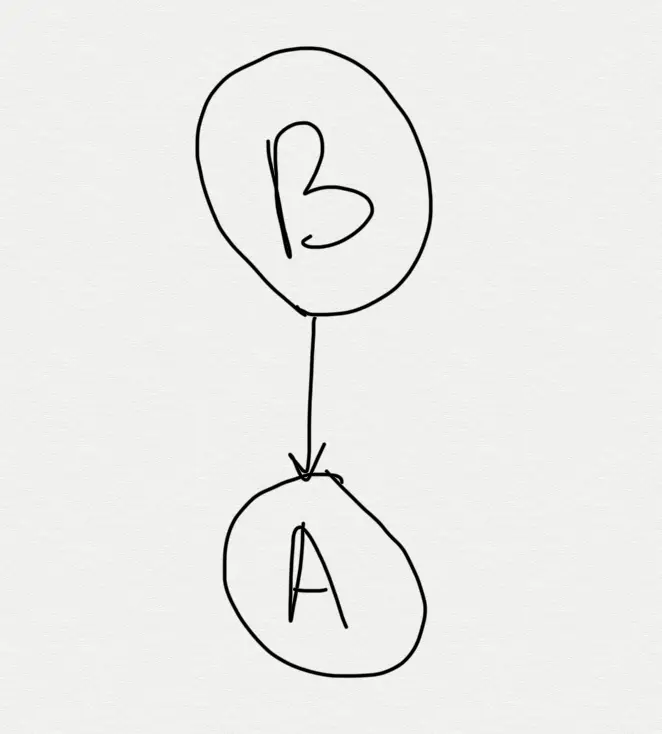
Consider following project:
- Module
A - Module
B Adepends onB
Normally, to build A one would need to build B (and all of its dependencies) first. Which is what Gradle does.
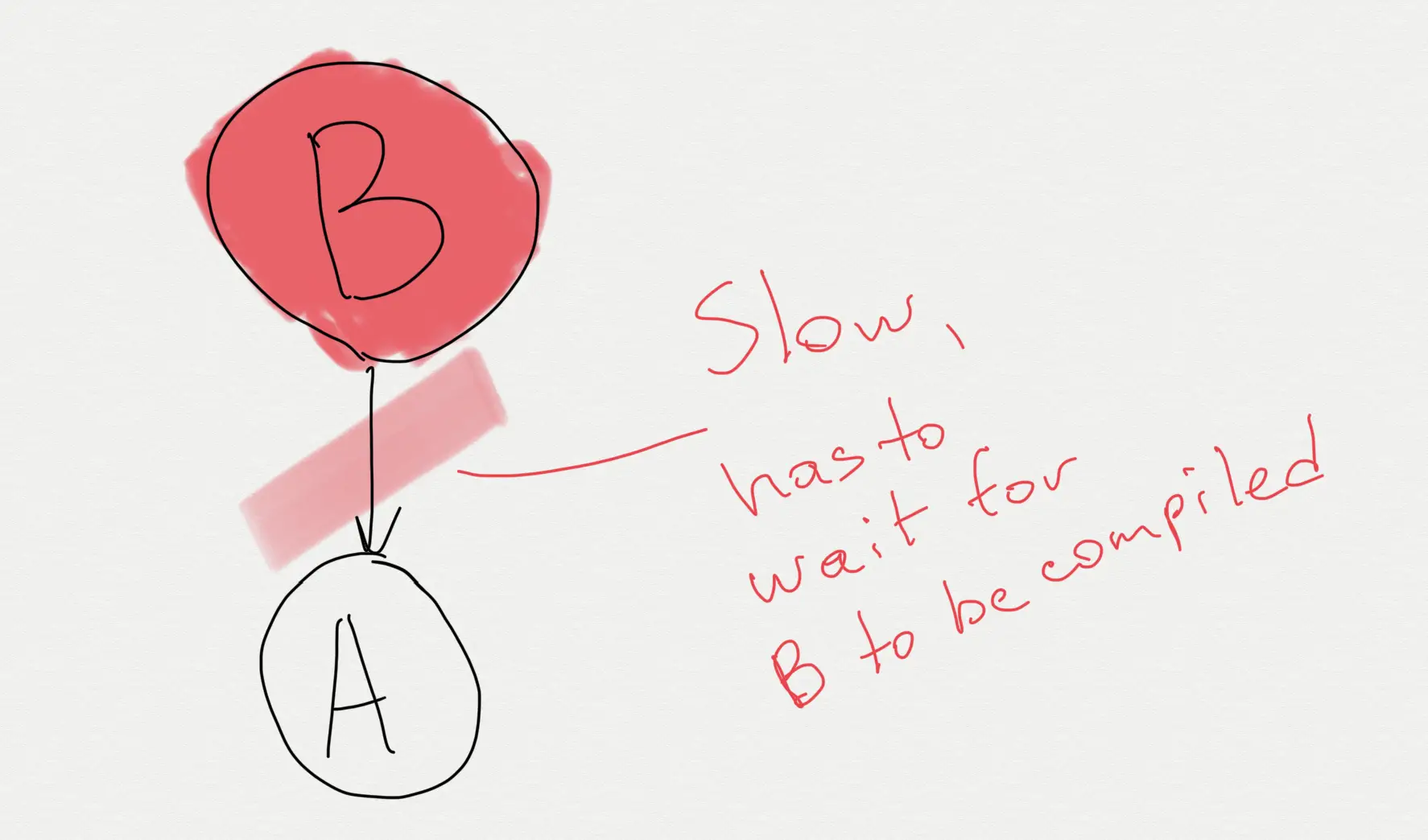
This, however, is inefficient. Not just in large projects, but in general. It gets especially bad in large projects though.
Because of such strict build ordering, Gradle often can't take advantage of hardware (particularly multicore CPUs) to its full degree. Certain modules become long living "locks" in the build graph, blocking compilation of dozens of other modules just because they and their dependencies have to be built first.
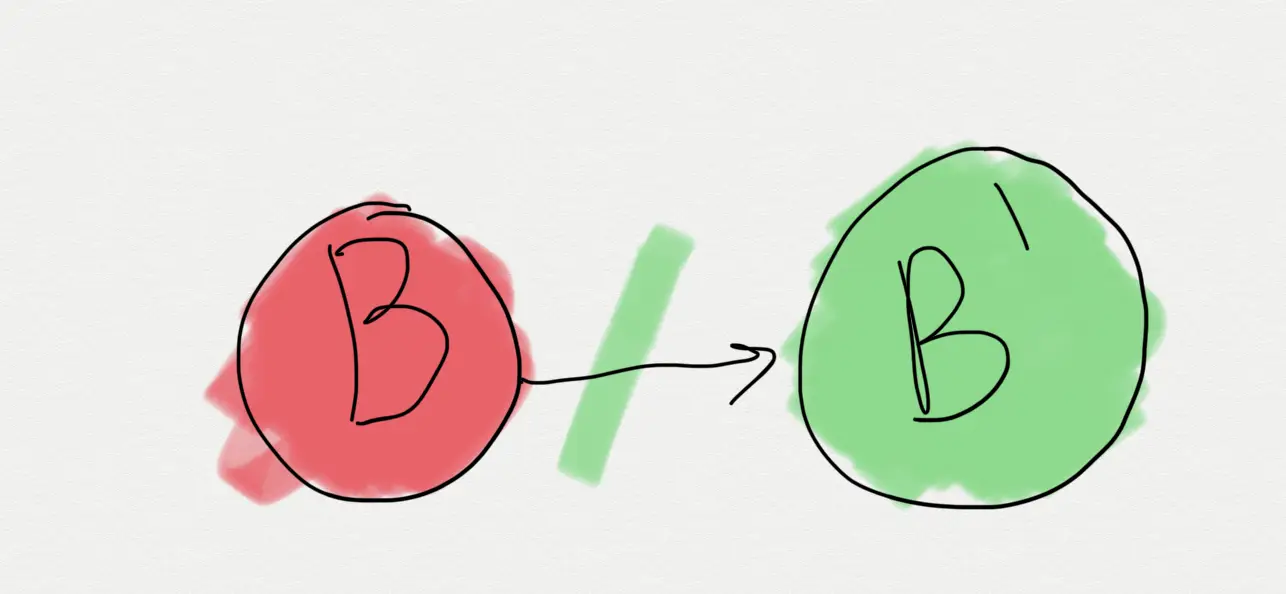
Gradle should build modules against ABI of their dependencies.
Proposed Solution: Build Against ABI
As mentioned above, consider following setup:
- Module
A - Module
B Adepends onB
Normally, to build A you would need to build B and all of its dependencies first.
But actually, A doesn't need the B to be built at all. What's important for A is the ABI of B.
Now we have to step back and clarify that ABI has different meanings. Generally it means Application Binary Interface, but level of detail can vary on compiler/linker/etc.
For the sake of this discussion though, you can think of ABI as a stripped out version of public entities (classes, methods, interfaces, etc) in a module.
For example, consider following Java class:
public class MyClass {
private String x;
public void a() {
this.x = b();
}
private String b() {
return incrediblyComplicatedLogic.execute().explain()
}
public static Runnable c(String s) {
return () -> { … }
}
}
A human-readable version of ABI for MyClass can be represented like this:
public class MyClass {
public void a() { throws NotImplementedException() }
public static Runnable c(String s) { throws NotImplementedException() }
}
As you can see, only public members were left. But that's not all, implementation details are gone too!
As you can imagine, extraction of ABI can be much much much more faster than actual compilation, to compute ABI you don't need to compile the code.
If you seek to understand how ABI can be represented in different languages, here are few examples:
- Pretty much any JVM language can have ABI in form of class files with only public members and no implementation details*
- C (and optionally C++) has header files that represent ABI
- Compile toolchains that are designed to be build against sources can have ABI represented as source files with only public members and no implementation details, similarly to header files*
*There are caveats, of course:
- Some languages like Kotlin have compile-time inlining. This requires ABI to contain source/byte/machine code of functions that needs to be inlined, thus requiring at least partial compilation
- Some languages allow compile-time code generation. This can result in tricky situations when publicly exposed type needs to be generated by compiler first, thus requiring at least partial compilation/code generation.
However, in many many cases ABI is extractable and this technique is very successfully used in Bazel and Buck, allowing them to fully utilize hardware resources by removing long living locks from the build graph.
Interestingly, Gradle is already somewhat aware of ABI details for incremental compilation of many languages it supports.
Proposed changes:
- Gradle should extract ABI from modules written in popular languages and build modules against ABI
- Gradle should link against actual binary produced by a module if executable or fat/uber binary is being requested
- Gradle should extend current compile avoidance based on
api/implementationto the ABI, thus not rebuilding modules if ABI of their dependencies didn't change (which is a very common case when changes only affect implementation details of functions/classes/etc)
Result:
Such a change will allow Gradle to utilize hardware with much higher efficiency, saving tremendous amount of time in execution phase.
Conclusion
Gradle is a great generic build system. While it has very strong upsides like actually incremental compilation, it has major design issues which if not fixed will result in Gradle losing its grounds now that Bazel is getting momentum after years of being a closed source system.
Worth noting that I'm not aiming for a perfect build system, nor did I describe all problems of Gradle in this article, but rather I want Gradle to stand up against Bazel and Buck and be scalable for large multi-module projects so we get more choice as users. If I would want to aim for a perfect build system, that wouldn't be Gradle, nor Bazel nor Buck.
With that being said,
Godspeed to the Gradle team!
Thanks to Artur Dryomov for review!
Replies in twitter: https://twitter.com/artem_zin/status/1072438196103995392
Specifically, please check thread with replies from a Gradle core team member Cédric Champeau
"if ABI of their dependencies didn't change (which is a very common case when changes only affect implementation details of functions/classes/etc)" This is already the case for Java.
— Cédric Champeau (@CedricChampeau) December 11, 2018
Fair! Gradle doesn't have to reinvent it though, there are open source projects doing ABI extraction from sources and if anything build system maintainers should push language developers to provide tools for that, similarly to how Google pushes JetBrains to work on Kotlin ABI
— Artem Zinnatullin (@artem_zin) December 11, 2018
for configuration, the new lazy API should significantly improve things since we would only configure what needs to be. There's a migration path too.
— Cédric Champeau (@CedricChampeau) December 11, 2018
sure, lazy configuration is a bandaid applied to the wound :) it should've been that way since beginning, nonetheless I'm really happy the API is there now
— Artem Zinnatullin (@artem_zin) December 11, 2018
We however still suffer from 20 sec configuration with Gradle 5.0 and AGP 3.4.0-alpha07 which is pretty lazy :(
Yep, I'm not saying that this is the problem and actually I like how incremental Gradle is inside a given module compared to Bazel/Buck
— Artem Zinnatullin (@artem_zin) December 11, 2018
The problem is that Gradle waits for a module to be compiled to unblock its consumers, which creates bottlenecks in build graph :(
so your post summarizes some pain points, but we are on it. The solutions might differ, but it's something we're fully aware of and currently working on. The situation on Android is much harder also for backwards compat reasons.
— Cédric Champeau (@CedricChampeau) December 11, 2018
we also don't want to rely on declaration of intent "believe me I'm safe" because lots of people just don't understand what it means. We'd rather infer it.
— Cédric Champeau (@CedricChampeau) December 11, 2018
No worries, thanks for writing this down, it actually aligns pretty well with our plans. Not 100% but pretty well :)
— Cédric Champeau (@CedricChampeau) December 11, 2018